“外链资源文件整理”是《AhrefsRadar外链雷达》中帮助您进行文件整理的一个辅助工具库,当前的版本包含的功能有:
文件合并、文件分割、去重复以及提取或排除功能。
使用说明与技巧:
一、文件合并
1)选择要合并的文件(多选)
点“选择文件”,选择需要合并的2个或2个以上的TXT文件。
2)结果保存位置
不需要自己选择,与所选需要合并的文件同目录。
3)选择完毕后点“开始合并”,就会自动合并所选的多个TXT,生成的文件名格式为:Merge_时间.txt
二、文件分割
1)选择要分割的文件
点“选择文件”,选择需要分割的TXT文件,选择后会自动计算所选TXT行数,显示在“外链资源总条数”
2)每个分割文件的条数
设置一个数值,表示生成的每个分割文件的条目数。
3)结果保存位置
不需要自己选择,与所选需要分割的文件同目录。
4)选择完毕后点“开始分割”,就会自动分割所选的TXT,生成的分割文件名格式为:所选文件名_part序号.txt
三、去重复
1)选择要去重复的文件
点“选择文件”,选择需要去重复的TXT文件。
2)去重复类型
可以根据自己的需要,选择“按行去重复”、“按URL去重复”或“按域名去重复”,其中“按行去重复”可以处理任何数据,而“按URL去重复”和“按域名去重复”都是针对URL数据进行去重复,不能处理普通数据。
3)结果保存位置
不需要自己选择,与所选需要去重复的文件同目录。
4)选择完毕后点“开始去重复”,就会自动按设置的“去重复类型”去重复所选的TXT,生成的去重复后的文件名格式为:所选文件名_NoRepeat.txt
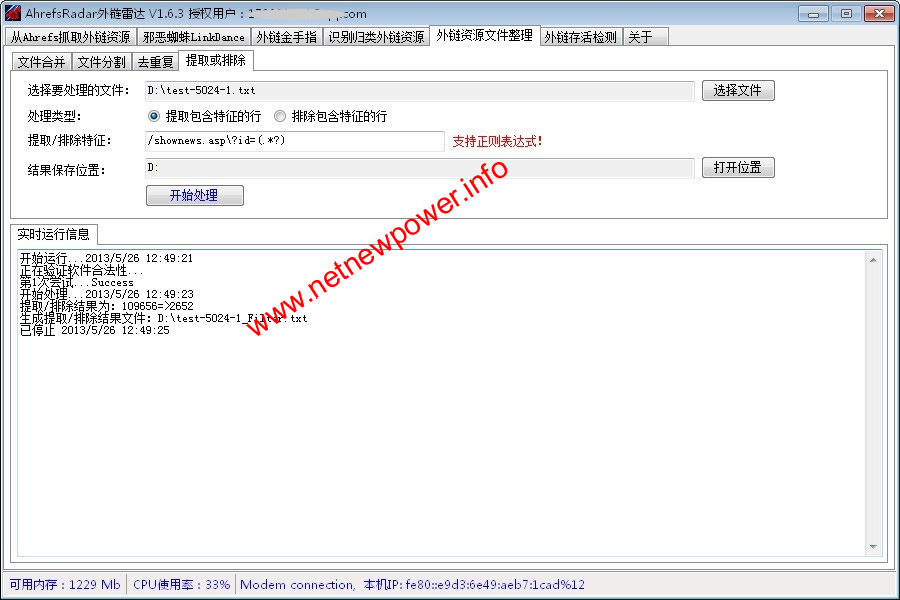
四、提取或排除指定行
1)选择要去处理的文件
点“选择文件”,选择需要处理的TXT文件。
2)处理类型
可以根据自己的需要,选择“提取包含特征的行”或“排除包含特征的行”,进行提取或排除操作,可以处理各种数据,不限于URL。
3)提取或排除特征
可以是普通字符串,也可以是正则表达式,灵活运用。
可以从一组URL中提取或排除你想要的某类资源,特征写法可以是:
/readnews.asp\?id=(\d+)
或
/forum.php\?mod=viewthread&tid=(\d+)
或
/forum.php\?mod=viewthread&tid=(.*?)
或
/member/(\d+)
或
/bbs/
等等。。。。。。
这个可以处理普通数据以及URL
在处理普通数据上可以是一个灵活的文本提取排除工具;
在处理URL上面其实和我们“识别归类外链资源”的URL特征法功能类似,只是这个适合自己细化操作某一或某几个类型;
4)结果保存位置
不需要自己选择,与所选需要处理的文件同目录。
5)选择完毕后点“开始处理”,就会自动按设置的“处理类型”去处理所选的TXT,生成的处理后的文件名格式为:所选文件名_Filter.txt
五、提取行中的指定值
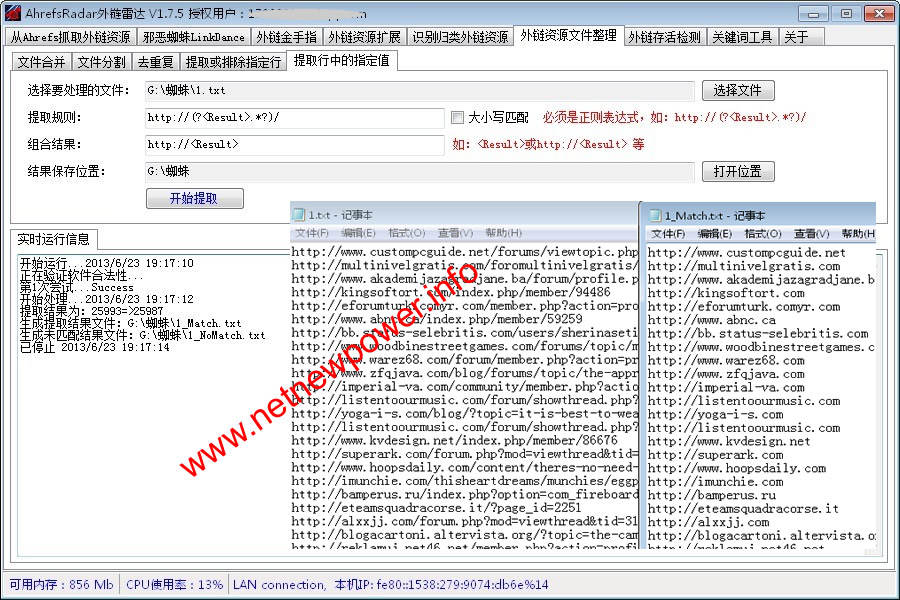
1)选择要去处理的文件
点“选择文件”,选择需要处理的TXT文件。
2)提取规则
提取是按行提取;
(?<Result>.*?)是一个用于匹配特定值的正则表达式,把它放到你想提取的内容的位置。
比如你想从一组URL中提取网站域名部分,可以这么写:
提取规则:http://(?<Result>.*?)/
组合结果:<Result>
3)组合结果
是指根据提取规则,获取到的值的结果表示形式
如果不做修改,只需要填写:<Result>
如果想做修改的,比如2)中想表示为网站首地址形式,那么组合结果可以这么填写:http://<Result>/
4)结果保存位置
不需要自己选择,与所选需要处理的文件同目录。
5)选择完毕后点“开始提取”,就会自动按设置的规则与组合结果提取所选的TXT,生成的处理后的文件名格式为:
所选文件名_Match.txt和所选文件名_NoMatch.txt,分别保存提取到的最终记过,以及没提取到值的行的内容。